コースウェアの作成は、一度の作り切りで終わるものではなく、別のコースウェアを作成するとき、以前作成した学習資源を再利用できれば利便性が上がると思います。SCORMは、コースウェアの概念、学習資源の管理支援、そしてコンテンツの実装に関して、コンテンツモデル、メタデータ、コンテンツパッケージに分類し、これらを総称してコンテンツアグリケーションモデルと呼んでいます。
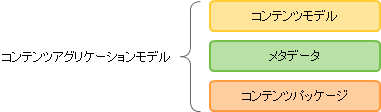
コンテンツアグリケーションモデルの理解は、再利用するにはどうすれば効率的か?ということを考えると、なぜSCORMは、そのような仕組みなのか、あれこれ注文をつけてくるのか見えてくるかもしれません。
コンテンツモデル
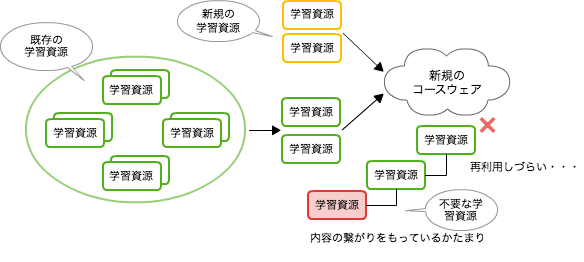
SCORMのコースウェアは、学習資源(SCO、アセット)の集合から成り立っています。新規に学習資源を作ることもあれば、既存のものを再利用して組み立てることもできます。しかし、1つの学習資源が、ほかの学習資源に依存していると、芋づる式に無関係なものまで含まれる危険性があります、そうすると再利用の利便性は落ちてしまいます。そのため、学習資源は、資源間の結びつきは弱く、独立性が高いことが求められます。コースウェアの設計者は、いつか再利用されることを意識して作る必要があります。
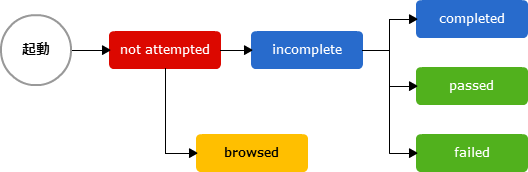
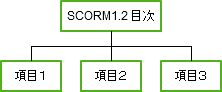
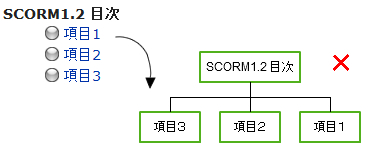
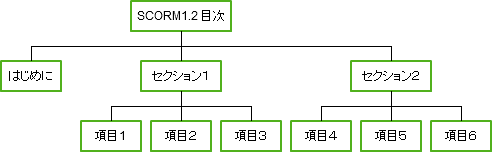
こうして作られた学習資源の集合は、どのような順番で提示するか学習の順番を決めます。フラットな並びでも、また1つの学習項目でも構いませんが、本の目次のような、章節項といった入れ子の階層構造も作ることができます。この体系化された構造のことをコンテンツモデルと言います。SCORM1.2では、学習の進行は、上から下へ(章→節→項)とリニアに進んでいきます。
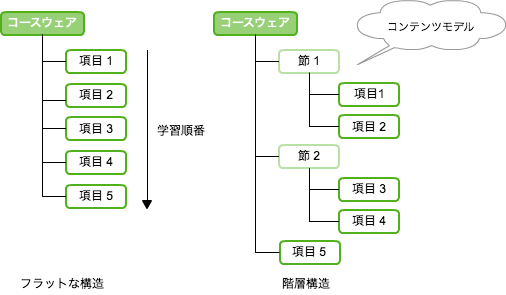
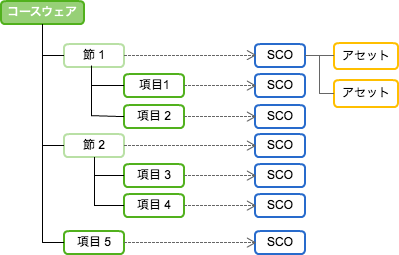
コンテンツモデルは、体系化した目次のような項目のモデルを示しただけです。学習資源との結びつきは、含まれません。コンテンツモデルに、学習資源としてSCOやアセットを集約した状態のことを、コンテンツアグリケーションと言います。
メタデータ
多くのコースウェアを作成して、学習資源が増えてきたら、再利用して新たなコースウェアを作ることは自然なことだと思います。まだ学習資源の数が少ない場合、何がどこにあるのかといった管理で困ることはないかもしれませんが、もし、それが数千、数万とある場合、さまざまなサーバーに分散されている場合、必要な学習資源を見つけるには、どうしたらいいでしょうか?
SCORMは、そのようなことに対して支援するため、1つの画像からコースウェアに対して、メタデータをつける事ができます。メタデータとは、コンピュータが認識できる対象物への意味づけ(属性)です。
例えば、コンピュータは、一枚の画像から、その画像が示す内容までは分かりません。何の絵が描いてあるかまでは分からないわけです。ウサギの絵が必要になった場合、画像に「ウサギ」という意味づけ(属性)が設定されていれば、検索によりその画像を見つけ出すことができます。
SCORMのメタデータは、学習コンテンツの特徴などを示した意味づけとなります。学習コンテンツは、どの言語(Japanese、English・・)で作られたか、シミュレーション型なのかドリル型なのかといった、情報を持たせることができます。
SCORMのメタデータには、割り当てる種類により3種類に分かれます。
- コンテンツアグリゲーションメタデータ
- SCOメタデータ
- アセットメタデータ
コンテンツアグリゲーションメタデータは、1つのコースウェア全体に対する情報です。SCO、アセットのメタデータは、コースウェアを構成する学習資産に対する情報となります。例えば、映像ファイルがある場合、アセットメタデータとして講義タイトル、作成日などを付けることができます。
メタデータは、SCORMの学習コンテンツの動作に直接関係しないため、記述しなくてもLMS上で学習コンテンツは動作します。LMSによっては、メタデータの情報を管理画面に表示するものもあるかもしれませんが、コンテンツリポジトリなどデータベースでコンテンツを管理することで、メタデータの便利さが実感できるかもしれません。
そのため、そのような検索システムを利用しない場合、あまりメリットが享受できないため、メタデータの記述は、省略することもあると思います。
コンテンツパッケージ
コンテンツパッケージは、コンテンツモデルやメタデータの具体的な記述を行い、さまざまなLMSで実行可能なコースウェアのフォーマットを提供することです。
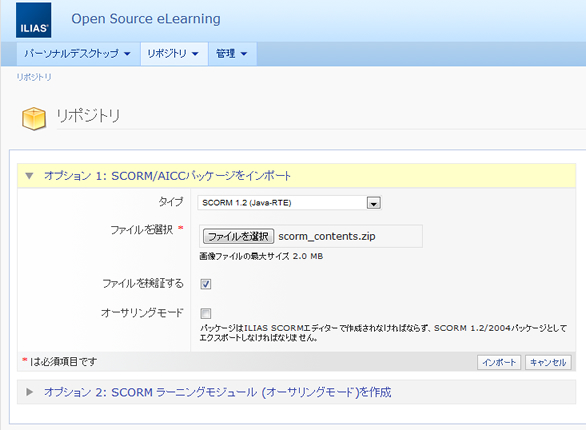
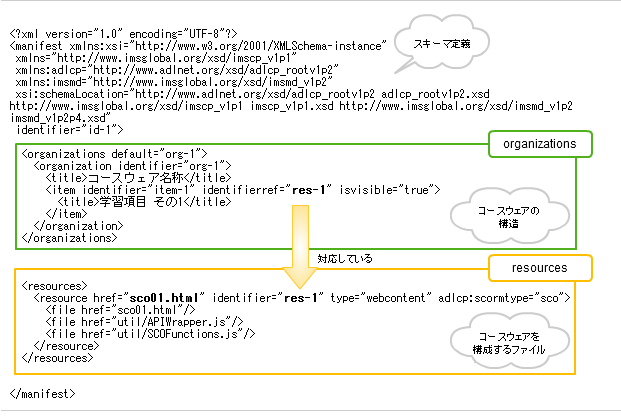
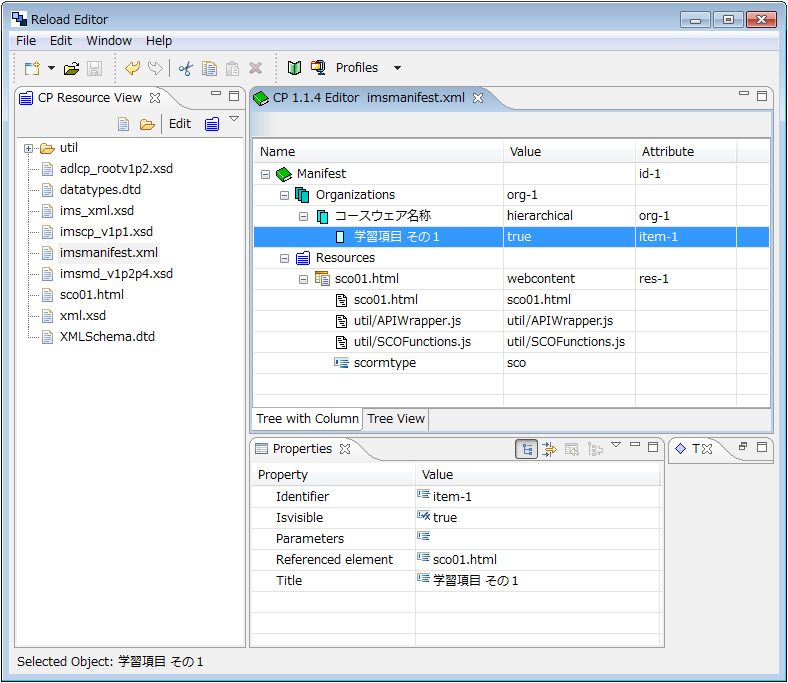
SCORMのコースウェアの作成は、学習資源(SCO、アセット)と、マニフェストファイルに分かれます。マニフェストファイルは、コンテンツモデルなど構造に関するものをXML形式で記述したものです。
学習資源は、基本的に個々が独立しているため、それらをどのように繋げて、制御をしたいのか、そういった記述は、すべてこのマニフェストファイルに記述します。マニフェストファイル1つで同じ学習資源でもコンテンツの挙動はまったく違うものになります。また、このファイルが無ければLMSは、コースウェアとして認識することができません。それだけとても重要なファイルです。
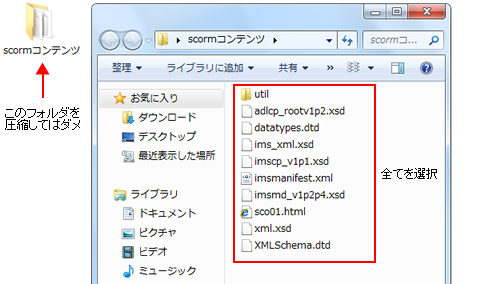
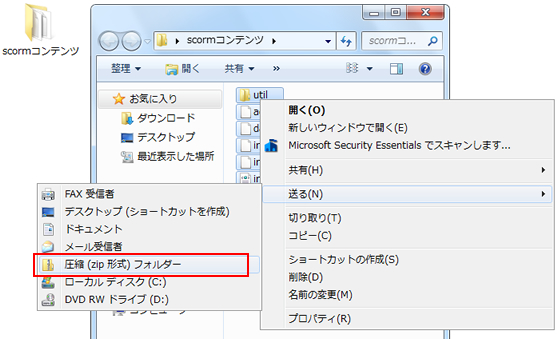
こうして作られたコースウェアは、最後に圧縮フォーマットのZIP形式で1つのファイルにまとめます。このファイルを特にPIF(ぴふ)ファイルといい、LMSにコースウェアを登録するときのファイル形式となります。