ステートメントへのインクルージョン
動詞は、ステートメントの一部として必要で、動詞を含めることはとても簡単なことです。ある経験により発生する行動を示すステートメントの動詞オブジェクトを verb プロパティとして設定するだけです。 動詞オブジェクトは、URI(IRI) を示す一つの id プロパティで構成されます。例えばこのような形式です。
{
id: "http://adlnet.gov/expapi/verbs/experienced"
}
これだけでも十分ですが、人は多少なり自身の母国語に近いものを好むようです。そのため、id プロパティと同じように、display プロパティを含めてください。display プロパティの値は言語マップ(対応する文字列の値を持つ言語コードの一覧)であり、 Tin Can API を国際化させるために必要な相互運用性の中心となります。これは同じ意味を持つ動詞ですが、人間が読み取れる display 値となります。
{
id: "http://adlnet.gov/expapi/verbs/experienced",
display: {
"en-US": "experienced"
}
}
言語値の追加は、RFC5646 の言語タグを使用して容易に言語マップに追加することができます。上記の “en-US” は、アメリカ英語の例です。
経緯
仕様策定の初期段階において、あらかじめ定義された動詞セットがありました。0.95バージョンの仕様策定において、動詞は自由に作成できることが適切と考え、id の完全な URI を持つリストは、オブジェクト フォームに移動されて仕様の範囲外になりました。これらの動詞が他の目的でも、もう使用されることが無いにもかかわらず、ADLは特にラーニング コミュニティ向けにデザインされた動詞リストを、まだ維持しています。 しかし、「attempted」 (履修した)、「experienced」 (体験した)、「passed」 (合格した)、「failed」(失敗した)、「answered」 (答えた)、そして「completed」 (完了した) などの動詞は、(もちろん URI の形で)従来の仕様とうまく適合するため、Tin Can で利用される動詞の中でも、共通的に使用される動詞になっています。Tin Can を利用するコミュニティは、その実践コミュニティの中で、認知されて利用するような、独自の動詞をコミュニティ依存の動詞セットとして作り出すと予想していました。そして例外として、ステートメントが無効になる特別な役割を果たす、事前に定義された動詞が仕様内に1つ含まれています。ステートメントを無効にするには、http://adlnet.gov/expapi/verbs/voided の id を持つ特別な動詞を含む新規のステートメントを、ステートメントのリファレンス(詳細は今後の投稿で説明)とともに、そのステートメントを受信すると思われる LRS に送信します。
過去時制
動詞は過去時制でなければなりません。Tin Can は本来、時系列に基づいて経験をトラッキングするように設計されています。ステートメントは経験のための記録(それは過去時制であり)したがって、動詞は過去の時制になります。直ちに記録された経験であろうとなかろうとも、体験そのものは既に過去のものでなければなりません。(これがステートメントがもはや「進行中」といったものを示さない理由の一つです。) 時間経過の概念は、一連の行動の繋がりの中で、潜在的には同じ体験内に存在します。それは積み上げられたステートメントから、意味を引き出すために必要とする相当量の複雑性がありますが、同時にコンテンツ作成者の想像力を高める柔軟性をもたらします。
実行可能性
URI として動詞ID が持つ意味は、多くの動詞はロケーション(URL)を解決できること、そのときに、それらにメタ情報を追加できることです。メタ情報は、少なくとも JSON として要求されたとき、仕様に従い、「name」(名称)と「description」(説明)プロパティを持つオブジェクトを含む必要があります。これらのプロパティは特に、動詞そのものについての説明(「display」プロパティの目的といったもの)ではなく、動詞についての情報を与えるために使われます。これはよいスタートで、動詞と Tin Can が進化するにつれて、動詞(と URI を使用するほかのアイテム)に関する情報を拡張できる手段を持つでしょう。私の中で、インターネットの純正主義者の信念に従うなら、動詞はURI であり、そして URL になる URI を選べるならば、すべての動詞は解決すべきです。ですが仕様では、動詞は解決する必要はなくオープンです。(そのとおり、私は常に純正主義者というわけではありません)
動詞を作るか、作らないか
本質的にそれは大した問題ではありません。最終手段として、どうしてもという以外は新しい動詞を作ることは避けてください。そうですね、Tin Can 導入がまだ時期尚早の段階で最終手段というのは、ちょっと言い過ぎかもしれませんが。動詞セットというものは、徐々に固定化されていくでしょう。Actor, Verb, Object のステートメントで利用する3つの構成要素を考えてみてください。このなかの動詞だけが、一貫して人々の経験を横断して一致させることができて、同じ actor の経験のさまざまな行動を示します。そのような2つの側面は、行動をレポーティングするときの基本であり、これから全ての新しい経験が、全く新しい動詞セットでレポーティングされてしまっては、その役割を果たすことができません。実践コミュニティが必要なのはこのためです。適応を通して動詞は牽引力を持ちます。動詞の自然な関連付けが増え、牽引力を持つようになるとシステム作成者は、Tin Can のような仕様が提供しようとしている相互運用性の基礎となるセマンティックな意味づけが頼りになります。ステートメントの作成者は、既に動詞がないかよく探して、あるならば活用すべきです。
レジストリ
私たちは、動詞(そして、ほかのURIベースのコンポーネント)リストのことを registry(レジストリ) と呼び、その動詞リストを一つ作成しました。具体的には The Registry というもので、ここで元となる「動詞」を見つけることができます。現状、The Registry は ADL の動詞リストから構成されていますが、相互運用性を低下させる動詞の激増を防ぐために、ユーザーがきちんと整備されたプロセスを通して新たな動詞を作成できるように、(ブログ記事を書いていないときに)機能性の向上について取り組んでいます。もちろん私たちは、人々が新しい動詞を作成して、その動詞を利用することを防ぐことはできません。そして新しい動詞は時間の経過とともに必要になるでしょう。私たちは、これらの動詞が永続的(ステートメント作成に必要であるため)に使われること、そして問題解決に役立つ事を望んでいます。そのため、URI ベースの id で利用するドメインの名前空間 id.tincanapi.com を立ち上げました。The Registry の中で作成された動詞(及び他のアイテム)は、仕様で定義される、動詞に関連するメタデータを提供する解決可能なURLを持ちます。
意味というのは単語でない
動詞は手強いです。そして英語は(他の言語も、きっとそうだと思いますが)、それらの動詞を更に手強くする至上の言語です。これまでは、相互運用性を可能にするために、可能な場合は動詞を再利用すると言いましたが、しかしまた、独自の動詞セットを採用する実践コミュニティがあるだろうとも言いました。これらの2つのベストプラクティスは、相反する葛藤を含んでいます、それは一つの動詞がステートメントに応じて、異なる意味を持つ可能性があるということです。類義語と呼んでもいいでしょう。これがどれだけインパクトのあるものなのか、もう一つ言えば、動詞オブジェクトは、特定の単語ではなく、1つの意味に直接マップする識別子を持ちます。それゆえに特定のIDによる動詞オブジェクトの意味を見出すとき異なるケースでは、動詞の意味に一致する単語と意味が合わないことがあるということです。
Fired という単語は、よく引き合いに出されます、それは恐らく、ひとつに指定される単語だからでしょう。Fired は、状況によっては全く違う意味になり得ます。その文面が表す状況により、意味合いが全く変わることから、その動詞ID の意味を作り出す単語が鍵を握っています。問題はどのようにその単語を識別するかです。例えば、fired a gun (銃を発射する) と fired a cannon (大砲を発射する) は異なった動詞でしょうか?両者ともに発射物が急速に弾き出て行く様を意味するものです。したがって同じ動詞である、と主張する人もいるでしょう。つまり、白黒がはっきりしないグレーゾーンが残り、その部分をはっきりさせるにはステートメントを処理するシステム、そして究極的には私たちのような不確かな人間が、難解な意味を持つ文脈の関係性を考慮しながら、判断を下し、言葉の意味付けをしていかなければなりません。動詞や類義語を新たに、そして正しく作成するには、時間そしてどの意味を採用していくか、この二つが本当に唯一必要なことなのです。
※ この記事は、CC BY 3.0のもと、tincanapi.com の Deep Dive: Verbs を翻訳したものです。意訳のため正確さを求める場合、原文を読んでください。
(原文) http://tincanapi.com/2013/06/20/deep-dive-verb/
 従来のeラーニングの仕様は、堅牢なセキュリティに欠いていることはよく知られています。LETSI RTWSは、セキュリティのためのソリューションを提供しており、これは、良いスタートです。
従来のeラーニングの仕様は、堅牢なセキュリティに欠いていることはよく知られています。LETSI RTWSは、セキュリティのためのソリューションを提供しており、これは、良いスタートです。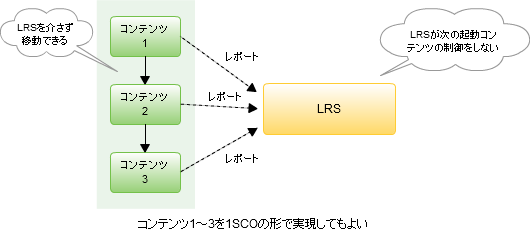
 Tin Can APIは、学習者に対して一つのプラットフォーム上(例えば、自宅のコンピュータなど)でアクティビティを開始した後、(モバイルフォン上のネイティブアプリのような)異なるデバイス上で、そのアクティビティを継続することができます。これはシンプルですが、強力な新しい機能です。そして、従来のeラーニング規格ではできませんでした。
Tin Can APIは、学習者に対して一つのプラットフォーム上(例えば、自宅のコンピュータなど)でアクティビティを開始した後、(モバイルフォン上のネイティブアプリのような)異なるデバイス上で、そのアクティビティを継続することができます。これはシンプルですが、強力な新しい機能です。そして、従来のeラーニング規格ではできませんでした。 従来のeラーニングの仕様のほとんどは、コンテンツをトラッキングするために常時接続を必要とします。
従来のeラーニングの仕様のほとんどは、コンテンツをトラッキングするために常時接続を必要とします。