誰も経験者がいない場合、LRSにステートメントは記録されますか?
抽象的な概念に伴う問題
Tin Can API は経験情報を記録するためにデザインされていますが、1つの前提条件として、個人あるいはグループが経験者として存在しなければなりません。アクタを書くことは、Tin Can のステートメント上、それは 「I (私)」 として扱われ、つまり文法的には主語になります。
Tin Can ステートメントを作るとき、抽象的な概念がたくさん出てきます。そして、一見してステートメント 「I (私)」 の定義は単純にみえるため、手始めにそこから始めることは現実的です、しかし残念ですが実際は、そう単純ではありません。「私はいったい誰なのか?」という問いかけは、世代を超えて問われ続けるような大きなもので、Tin Can であっても小さくならない問いかけです。そのような問題と折り合いをつけるには、あなたが 「I (私)」(もしくは 「royal we(私たち)」)を定義するだけでなく、相手の誰かに自分が誰であったのかを伝えられなければなりません。そして、さらに問題を複雑にすることに、あなたは「 I 」を アクタとせず、あなたの仲間 「me」(あるいは何人かの仲間 「us」)をアクタとして定義するケースがあることです。 「 myself 」 もいいでしょう。さて、代名詞については十分話しましたので、アクタに話しを戻します。
ステートメントの アクタの部分を理解するには、客観的に JSON オブジェクトの値(代入の右辺)に対する、キーやプロパティ(代入の左辺)が何になるのか、理解することです。最終的にステートメントは、値が代入されたプロパティの集まりから構成されます。アクタはそのようなプロパティの一つで、アクタは「 Agent 」(あるいは「 Group 」)でなければなりません。
これはアクタは、あとから値が決定されるプレースホルダー(あるいはポインタ(参照))のため、それ自体に特別な意味を持たないためです。
言い換えれば、私たちはアクタを意味を持った名詞、あるいは、何らかのオブジェクトタイプであると考えてはいけません。アクタは特定の値を指しているポインタ(参照)として考えます。また、ステートメントのプロパティとプロパティが保持する値の形式は、(小文字の)「 actor 」と大文字の「 Agent 」を使い区別している点に気が付いてください。ただ私の妻は、セマンティックスを振り回しているだけと私に指摘するのですが、もし彼女が開発者なら、セマンティックスは、私(私達)の作業にとって非常に重要なことで「正しいことだ」と、言い返したいところです。(ただ、彼女は開発者ではないので、すべて言い返すようなことはしません、頭が上がらない立場なので。)
エージェントとグループの定義
エージェントとは、オブジェクトタイプの一つで確実に言えることは、逆関数識別子で表現しなければならないため一貫性があり、同一のエンティティ(実体)までトレースバックできる一意の ID を指します。逆関数識別子は、エージェントを表すいくつかの形式をとることができ、メールアドレス(またmbox)が最も分かりやすい形式です。人であれば読み取れるメールアドレスに加えて、1つのエージェントは、メールアドレスに含まれる SHA1 ハッシュによって指定することもできます(ハッシュは IRI でなければならないので、「 mailto 」の部分も含まれます。)
{
mbox: "mailto:info@tincanapi.com",
objectType: "Agent"
}
{
mbox_sha1sum: "f427d80dc332a166bf5f160ec15f009ce7e68c4c",
objectType: "Agent"
}
電子メールアドレス以外にも、エージェントは OpenID の URI を利用して一意に指定することができます。電子メールが、まだかなり広く受け入れられている状況でも、 OpenID は、いくつかの領域でうまく行っています。仕様書では、エージェントは対象システムが持つ固有識別子で特定できるコンビネーションを使い、多くのシステムが持つ特有のバリエーションを使用することができます。Twitter.com で言えば、「Twitter handle(ツイッター ハンドル)」が、そのシステムでの固有表現になり、そのコンビネーションは、単に「 Account(アカウント)」として知られているものです。いくつかのシステムが、現れては消えていくなかで、やがて電子メールアドレスの終焉を目にするかもかもしれません、システムの固有IDに加えそのシステムのエンテイティ(概念としてのアカウント)の固有ID の概念は、その仕様が存在する限り十分に柔軟性を持たせる必要があります。
{
account: {
homePage: "http://twitter.com",
name: "projecttincan"
},
objectType: "Agent"
}
注意すべき重要な点は、エージェントは、利用可能な複数の逆関数識別子を持つことができたとしても、エージェントオブジェクトが、逆関数識別子にリンクして関連を持つことで、プライバシーの理由などから LRS が要求を拒否してしまうことを避けるためにも、一つだけを含むべきです。また、私たち人間がもっと簡単に利用しやすくするために、エージェントに「 name(名前)」を関連付けることが出来ます。
{
mbox: "mailto:info@tincanapi.com",
objectType: "Agent",
name: "Info at TinCanAPI.com"
}
上記の例では、明示的に ObjectType プロパティを Agent にしました。そのプロパティは、Agent か Group かの、いずれかである必要があり、また初期値が Agent の場合は、いつでも省略することができます。( actor プロパティの オブジェクトタイプみたいなものです。)
グループは、エンティティ(実体)を表現するオブジェクトタイプという点で、エージェントによく似ていますが、構成の全て、または一部、特に member プロパティを、列挙できる追加プロパティを持ちます。グループは、objectType プロパティに、グループ値を与えなければなりません。そして グループには、2つの種類があり、指名と未指名(匿名)があります。前者の場合、指名グループは、エージェントのように、逆関数識別子(または、固有識別子)を持っていて、member プロパティを含んでも含まなくても構いません。また指名グループが、リストを持つ member プロパティを含んでいても、それが完全なリストであると判断すべきではありません。これは、あるステートメントが、経験したメンバーエージェントの特定のサブセット(一部の人)のみ呼び出すことがあるためです。(おそらく、著名なメンバーエージェントや、最大寄与数を持つメンバーエージェント、最も整理されているメンバーエージェント、または、最初に到着したメンバーエージェント。)後者の例では、未指名、つまり匿名グループは固有に指名された情報との関連付けがありません。そのために逆関数識別子を持ちませんが、member プロパティを含まなければなりません。バージョン1.0.0 の時点での仕様では、この場合のメンバーリストは完全なリストである必要はなく、オープンなままをベスト·プラクティスとしています。これは、ほかのメンバーエージェントとステートメントのその部分を関連させる方法がないからです。未指名グループを、同一のグループとして同じ一組のメンバーエージェントと関連付けることは自然と成りうる傾向ですが、仕様上、実装するシステムは、このような想定を行うべきではないことに注意してください。更に言えば、どちらの種類のグループメンバーリストもエージェントのみ含むものでなければなりません。そのため、グループを入れ子にすることはできません。
{
mbox: "mailto:info@tincanapi.com",
name: "Info at TinCanAPI.com",
objectType: "Group",
member: [
{
mbox_sha1sum: "48010dcee68e9f9f4af7ff57569550e8b506a88d"
},
{
mbox_sha1sum: "ca3ffdb44c4727137e29ebf42ee80c2afdd8d328"
},
.
.
.
]
}
{
objectType: "Group",
member: [
{
mbox_sha1sum: "90f96ca8c3ae315f0e40df4e16772eb6d05e3937"
},
{
mbox_sha1sum: "ca3ffdb44c4727137e29ebf42ee80c2afdd8d328"
}
]
}
ステートメントに話を戻して
さて、ここまで、私たちは Agent/Group オブジェクトについて学び、actorプロパティのオブジェクトと理解したところで、次を見てみましょう。※ただ、ステートメント内には他にも、同じようにエージェントを使用することがあります。例えば、前述した“me 私”の例では、“ Sam (エージェント1) helped me (エージェント 2) ”(サムは私を助けた)といった同じようなステートメントを作るために、object プロパティの中に自身の Agent または Group (“us”) を置くことができます。その場合は、そのステートメントは、2つのエージェントを使用します、actorプロパティは、今までどおり1つ含み(この場合 Sam )、object でもう一つ使います(この場合 Brian(または me ))。エージェントやグループはステートメントの” instructor “としてステートメントの ” context ” の中に含めることができます、そうすることで、Brian (アクタ) learned Tin Can from Ben ( instructor ).”(「ブライアン(アクタ)はベン(instructor)から Tin Can について学んだ」)というステートメントを作ることができます。また、context は team プロパティをも含めることができますが、その場合は Group である必要があります。
最後に、エージェントはステートメントの authority プロパティを設定するために利用されますが一般的にステートメント作成でその記述がない場合、それは LRS によって作成されます。(” authority “(認証)に関しては今後詳述します)
ステートメント以外のこと
エージェントはステートメント構造において、最も重要な役割を果たす部分であり、クエリ可能である必要があります。エージェントオブジェクトは、 actor や object プロパティに一致するステートメントを取得するために、エージェントのクエリパラメータを通じてステートメント API に渡されます。他の可能性がある場所として1つでもエージェントが存在するステートメントを見つけるために「 related_agents 」のクエリフラグをオンにしてリクエストを送ってください。エージェントは、Agent Profile として呼ばれる、独自のAPIメソッドを持つすばらしいものです。Agent Profile は将来に向けて自分自身のポストを保証するものですが、今は LRS において特別なエージェントと任意のデータを関連付けることができることを知っておけば十分でしょう。1つのユースケースでは、ユーザプリファレンスを格納しています。Agent Profile と共に、エージェントはまた、API ステートコールに組み込まれています。
潜在的な問題
多くの場合、たくさんのグループに所属するだけでなく、最近では、人はいくつもの逆関数識別子を持っています。私は個人的に、Eメールアカウント3つ持っていますが用途に応じて使い分けてをしています。ひとつは個人用で、もうひとつは仕事用、そして最後のひとつが、いろいろな用途に使うものです。それらは技術的にドメインエイリアスを持っていて、約10個のドメインネームがあります。これらはそれぞれ、別個の逆関数識別子と考えることができ、そうすると、私は単にEメールだけでも約30 もの識別される手段を持っていて、そして、さらに少なくとも10もの公開しているプロフィール( Twitter、Github、 Facebook、 LinkedIn、 Google+ など)を持っています。それら、全てが「アカウント」という概念を持ち、Tin Can APIとのやり取りで利用できます。そして、それらは公共のものです。ここで重要な点は、Tin Can API で動作するシステムは、実際のところ「人」の特定識別子をいくつでも有することができる点を考慮する必要があります。
それに加えて、すべての逆関数識別子の場合において、私たちは Eメールアドレスあるいはアカウントが共有されているかどうかまで知ることはできません。そのため、エージェントが人とゆるく結びついている可能性がある一方で、一つのアカウントがひとりの人間を表現していると想定すべきではないのです。このことから私たちは、アカウントはひとりの人であると決めてかかるべきではないでしょう。さらに時間の問題やメールアドレスやアカウントは、所有者が変更される可能性があるという現実があります。例えば “ info@tincanapi.com ” というメールアドレスはあらゆる人に送信することができますが、“ brian@example.com ” というメールアドレスは Brian Miller から Brian Smith に所有者が変わるかもしれません。結局、それが timestamp プロパティが存在する理由のひとつになります。しかしそれについては後の記事で触れようと思います。
さあ、ステートメントを作ろう!。
※ この記事は、CC BY 3.0のもと、tincanapi.com の Deep Dive: Actor/Agent を翻訳したものです。意訳のため正確さを求める場合、原文を読んでください。
(原文) http://tincanapi.com/2013/06/05/deep-dive-actor-agent/
 従来のeラーニングの仕様は、堅牢なセキュリティに欠いていることはよく知られています。LETSI RTWSは、セキュリティのためのソリューションを提供しており、これは、良いスタートです。
従来のeラーニングの仕様は、堅牢なセキュリティに欠いていることはよく知られています。LETSI RTWSは、セキュリティのためのソリューションを提供しており、これは、良いスタートです。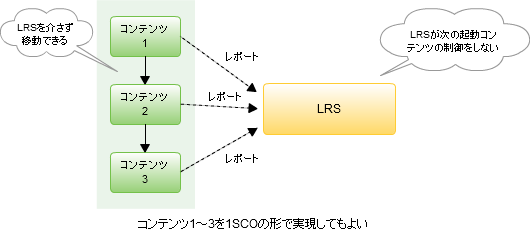
 Tin Can APIは、学習者に対して一つのプラットフォーム上(例えば、自宅のコンピュータなど)でアクティビティを開始した後、(モバイルフォン上のネイティブアプリのような)異なるデバイス上で、そのアクティビティを継続することができます。これはシンプルですが、強力な新しい機能です。そして、従来のeラーニング規格ではできませんでした。
Tin Can APIは、学習者に対して一つのプラットフォーム上(例えば、自宅のコンピュータなど)でアクティビティを開始した後、(モバイルフォン上のネイティブアプリのような)異なるデバイス上で、そのアクティビティを継続することができます。これはシンプルですが、強力な新しい機能です。そして、従来のeラーニング規格ではできませんでした。 従来のeラーニングの仕様のほとんどは、コンテンツをトラッキングするために常時接続を必要とします。
従来のeラーニングの仕様のほとんどは、コンテンツをトラッキングするために常時接続を必要とします。