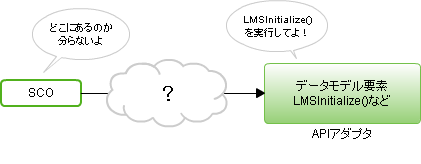
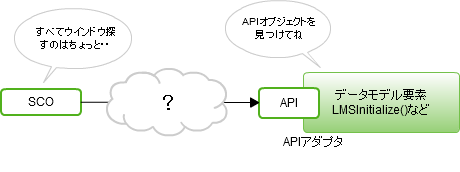
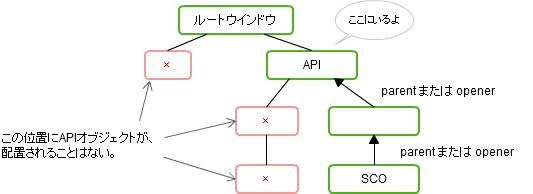
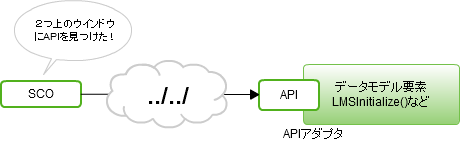
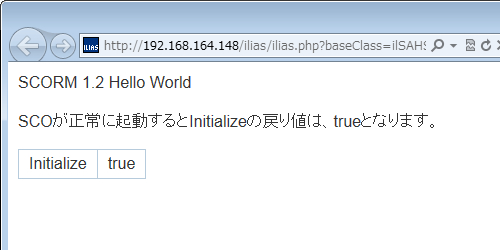
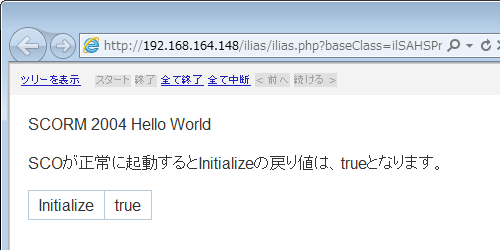
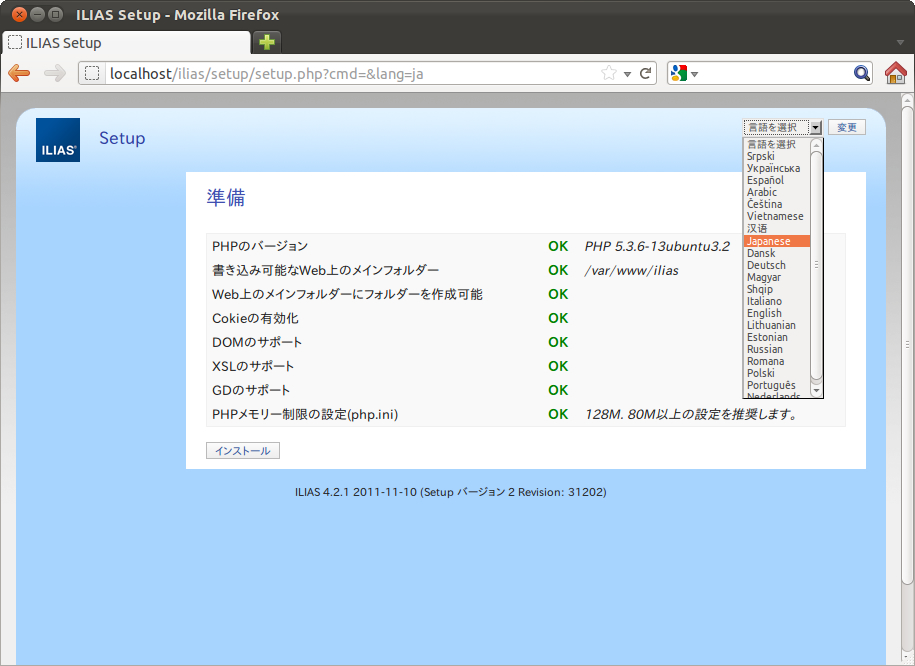
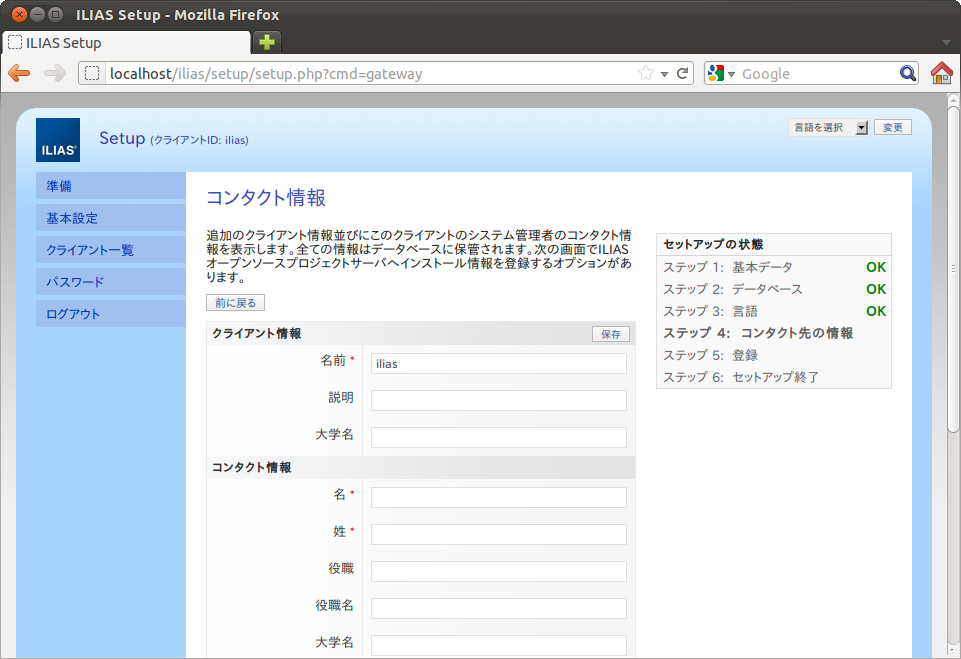
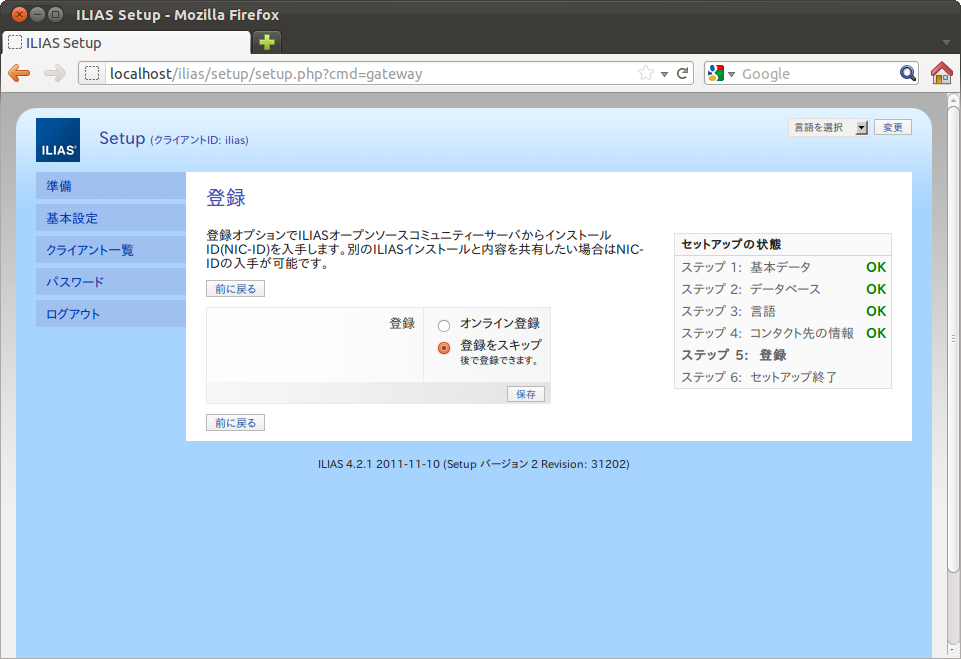
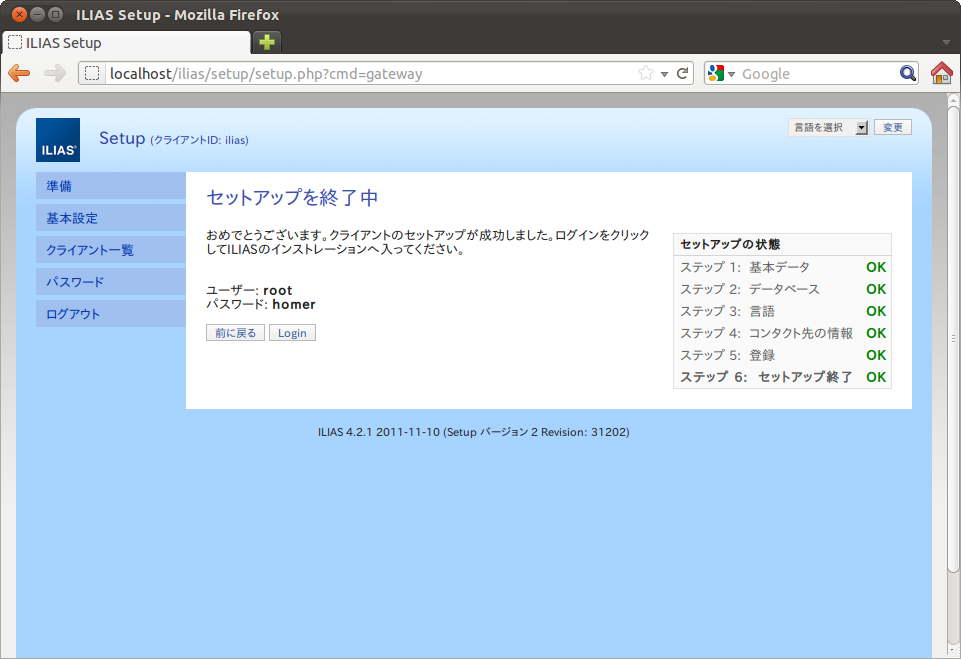
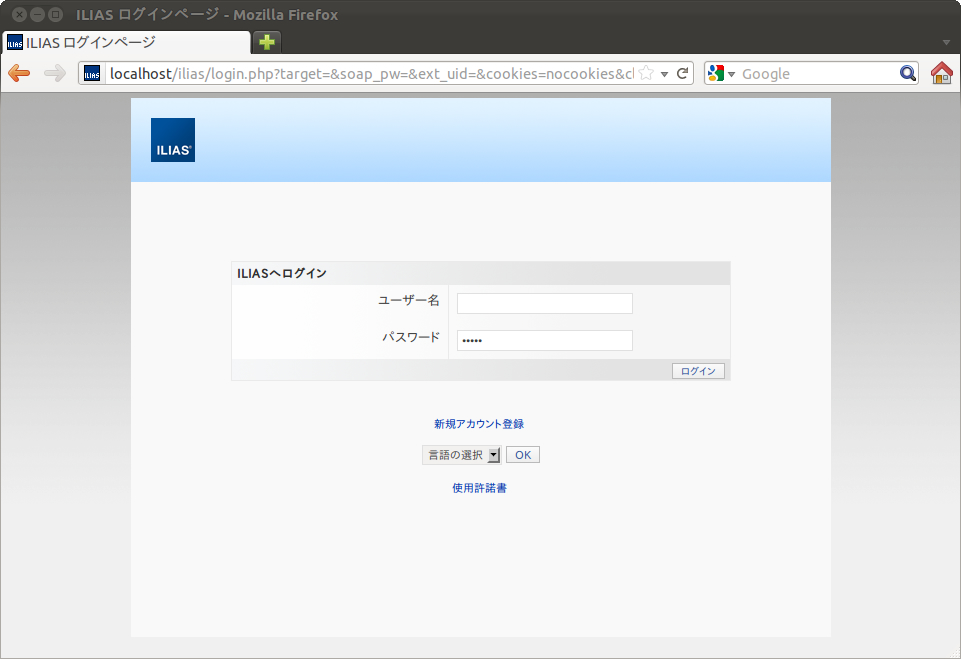
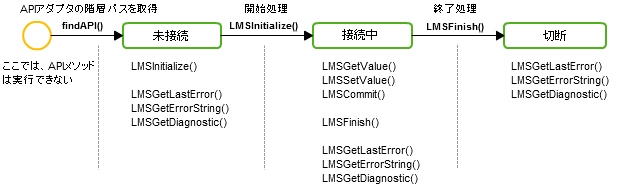
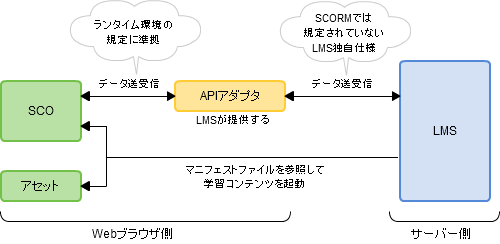
SCORM1.2 ランタイム環境のデータモデル要素は、49個あります。LMSGetValue()、LMSSetValue()の引数として利用します。
SCORM1.2は、LMSに対して3つの適合性カテゴリ(LMS-RTE1, LMS-RTE2, LMS-RTE3)というものがあります。これは、データモデル要素がどのくらいLMSに実装されているか分類したものです。
- LMS-RTE1 : LMSは、必須条件のデータモデル要素をすべて実装している
- LMS-RTE2 : LMSは、必須条件および、1つ以上、オプションのデータモデル要素を実装している
- LMS-RTE3 : LMSは、必須条件および、オプションのデータモデル要素をすべての実装している
※ 必須およびオプションのデータモデル要素を1つでも実装すれば、LMSは、LMS-RTE2となります。
|
No
|
実装条件
|
データモデル要素
|
|
1
|
必須
|
cmi.core._children LMSがサポートするcmi.core要素のリストを取得する |
|
2
|
必須
|
cmi.core.student_id 学習者のIDを取得する |
|
3
|
必須
|
cmi.core.student_name 学習者の氏名を取得する |
|
4
|
必須
|
cmi.core.lesson_location SCOを終了時、現在の位置から、再度、学習開始できるように、現在のSCOの位置を登録 学習再開時、終了時のSCOの位置から学習を始められるように、SCO終了時の位置を取得する |
|
5
|
必須
|
cmi.core.credit 履修記録が上書き可能(credit)か不可能(no-credit)か、状態を取得する |
|
6
|
必須
|
cmi.core.lesson_status 学習状況のステータスの登録 / 取得する |
|
7
|
必須
|
cmi.core.entry 現在のSCOが、初回受講か中断から再開したものか、すでに完了しているか、状態を取得する |
|
8
|
必須
|
cmi.core.score._children LMSがサポートするcmi.core.score要素のリストを取得する |
|
9
|
必須
|
cmi.core.score.raw 学習者の得点を登録 / 取得する |
|
10
|
必須
|
cmi.core.total_time 個別のSCOで費やした学習時間の総計を取得する |
|
11
|
必須
|
cmi.core.exit SCOを終了するときの理由を登録 (タイムアウト、一時中断、ログアウト、正常終了) |
|
12
|
必須
|
cmi.core.session_time 1つのSCOに費やした学習時間を登録 |
|
13
|
必須
|
cmi.suspend_data SCOごとに学習再開時必要となる情報を登録 学習再開時、登録した情報を取得する |
|
14
|
必須
|
cmi.launch_data SCOの起動時にマニフェストファイル内の<adlcp:datafromlms>要素を取得する |
|
No
|
実装条件
|
データモデル要素
|
|
15
|
オプション
|
cmi.core.score.max 最高得点の設定を登録 / 取得する |
|
16
|
オプション
|
cmi.core.score.min 最低得点の設定を登録 / 取得する |
|
17
|
オプション
|
cmi.core.lesson_mode SCOの動作モードの取得する |
|
18
|
オプション
|
cmi.comments 学習者が記述したコメント(文字列)を登録 / 取得する |
|
19
|
オプション
|
cmi.comments_from_lms LMSからのコメントや注釈を取得する ( ”” 空文字が多い) |
|
20
|
オプション
|
cmi.objectives._children LMSがサポートするcmi.objectives要素のリストを取得する |
|
21
|
オプション
|
cmi.objectives._count LMSが保持している現在の学習目標の数を取得する |
|
22
|
オプション
|
cmi.objectives.n.id n番目のSCOの学習目標の識別子を設定 / 取得する |
|
23
|
オプション
|
cmi.objectives.n.score._children n番目のSCOが使用しているcmi.objectives.n.score要素のリストを取得する |
|
24
|
オプション
|
cmi.objectives.n.score.raw n番目のSCOの学習目標に対する学習者の素点を設定 / 取得する |
|
25
|
オプション
|
cmi.objectives.n.score.max n番目のSCOの学習目標の最高得点を設定 / 取得する |
|
26
|
オプション
|
cmi.objectives.n.score.min n番目のSCOの学習目標の最低得点を設定 / 取得する |
|
27
|
オプション
|
cmi.objectives.n.status n番目のSCOの学習目標の試行後の状態(合格、完了、不合格、未完了、未実施、閲覧済み)を登録 / 取得する |
|
28
|
オプション
|
cmi.student_data._children LMSがサポートするcmi.student_data要素のリストを取得する |
|
29
|
オプション
|
cmi.student_data.mastery_score lesson_statusの状態を完了 / 習得に変更するために必要な合格得点<adlcp:masteryScore>を取得する |
|
30
|
オプション
|
cmi.student_data.max_time_allowed SCOに設定された制限時間を取得する |
|
31
|
オプション
|
cmi.student_data.time_limit_action 制限時間を越えた場合、SCOを終了 / 継続させるか、メッセージを表示するか動作<adlcp:timelimitaction>を取得する |
|
32
|
オプション
|
cmi.student_preference._children LMSがサポートするcmi.student_preference要素のリストを取得する |
|
33
|
オプション
|
cmi.student_preference.audio 音量を制御するために音量値の設定 / 取得する |
|
34
|
オプション
|
cmi.student_preference.language SCOが多言語で作成された場合、言語の設定 / 取得する |
|
35
|
オプション
|
cmi.student_preference.speed コンテンツの表示速度の値を設定 / 取得する |
|
36
|
オプション
|
cmi.student_preference.text ナレーション(音声)とキャプションテキストの表示モードを設定 / 登録 (テキストなし、音声あり / テキストあり、音声あり / テキストあり、音声なし) |
|
37
|
オプション
|
cmi.interactions._children LMSがサポートするcmi.interactions要素のリストを取得する |
|
38
|
オプション
|
cmi.interactions._count LMSが保持している現在の設問の数を取得する |
|
39
|
オプション
|
cmi.interactions.n.id n番目の設問に識別子(ID)を設定 |
|
40
|
オプション
|
cmi.interactions.n.objectives._count n番目の学習目標に存在する設問の数を取得する |
|
41
|
オプション
|
cmi.interactions.n.objectives.m.id n番目の学習目標内のm番目の設問に識別子を設定 |
|
42
|
オプション
|
cmi.interactions.n.time n番目の設問を解答した時刻を設定 |
|
43
|
オプション
|
cmi.interactions.n.type n番目の設問の形式を設定 true-false(真偽)、choice(多肢選択)、fill-in(穴埋め) long-fill-in(長文入力)、matching(一致)、performance(行動手順) sequencing(順序)、likert(調査【そう思う・やや思う、思わない】)、numeric(数値)、other(その他) |
|
44
|
オプション
|
cmi.interactions.n.correct_responses._count n番目の設問の正答数を取得する |
|
45
|
オプション
|
cmi.interactions.n.correct_responses.m.pattern n番目の設問に正答を設定 |
|
46
|
オプション
|
cmi.interactions.n.weighting n番目の設問に配点(重み付け)を設定 |
|
47
|
オプション
|
cmi.interactions.n.student_response n番目の設問に対する学習者の解答を登録 |
|
48
|
オプション
|
cmi.interactions.n.result n番目の設問の正誤結果 correct(正しい)、wrong(誤り)、unanticipated(予期しない)、neutral(どっちつかず)、x.x(CMIDecimal) |
|
49
|
オプション
|
cmi.interactions.n.latency n番目の設問の解答開始から終了までに要した時間を登録 |
※ SCORM1.2に対応しているLMSは、LMS-RTE3またはLMS-RTE2が多いと思います。No19のcmi.comments_from_lmsは、目的がはっきりしないため、LMSは意味のない空文字を返すことで、「とりあえず要素を実装」してLMS-RTE3の条件を満たしているように見えます。そのため、実装してないLMSは、ほかの要素を実装していてもテスト要件上、LMS-RTE2となります。